
税務署などに提出する法定調書をCDで提出したり、e-Taxで読込むためのテキストファイルを作成する場合は、シフトJIS(JIS第1水準及び第2水準)の文字を使用しなければなりません。
以前、JEFコードのオフコンシステムを運用していたため、データの変換が必要になりました。今更感はあるのですがその当時に調べたメモをまとめ直してみました。
※元になった資料は2022年当時のものです。ご利用になる場合は最新の情報を確認してくださいますようお願いします。
1.コンピュータの文字について
この説明も今更ですが、前提となる話ですので読み流してください。
メモリー内部の構造は網の目のようになっており、一つ一つをビットといい、電荷の有無など物理的な状態の違いで、ON/OFFを切り替えるようになっています。つまり、0か1の2進数です。8ビットで1バイトといい、これがコンピューターの最小単位です。
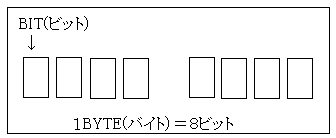
読むときは4ビットずつ区切ります。4ビットで表現できる数は 0000~1111(2の4乗-1)で、10進数では0~15です。10以降は数字が足りませんので英字を使用します。
10 は A (1010),11は B(1011)、12以後は順次 C(1100) D(1101) E(1110) F(1111) と割り振ります。これが16進数です。1バイトは16進数では00~FF、10進数では0~255です。
ここに半角の数字やカナをあてはめたのが半角の文字コードです。(漢字は2バイトで表現します。2バイトを1ワードといいます。)
2.ASCIIコード
コード体系はメーカーやOSにより異なりますが、そもそのの基本はACSIIコードです。
ASCII(アスキー)は、American standard Code For Information Interchange の略で、
7ビットの整数(0~127)で表現されます。
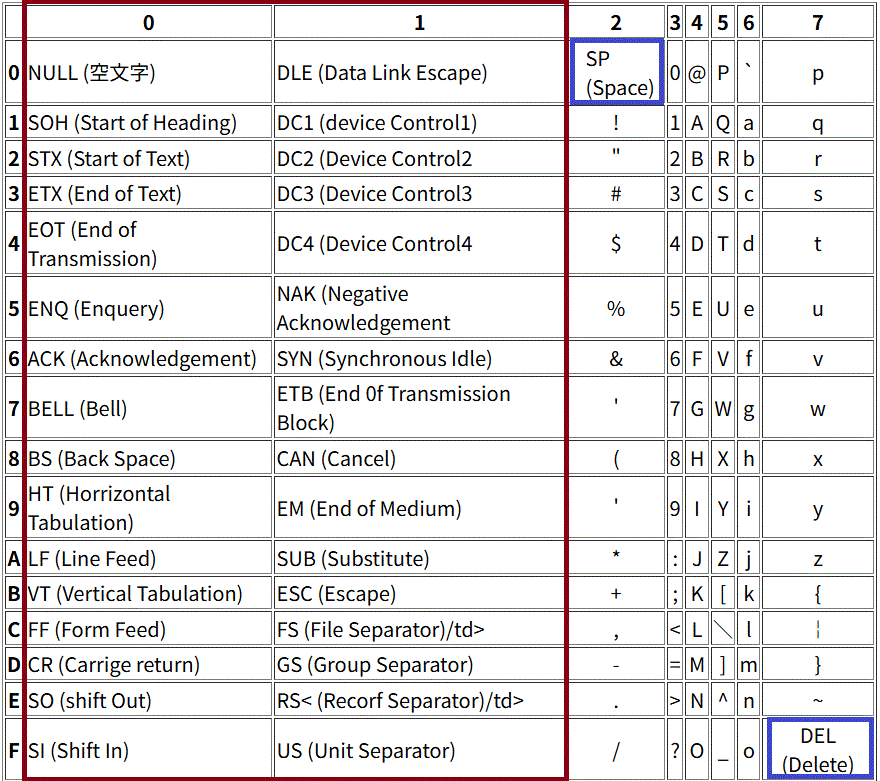
0x00 ~0x1F(制御コード)、0x20(空白)、0x7F(Delete)は、モニターやプリンター、及び通信を制御するためのコードで、印字することができません。 印字できる文字コードは残りの94(6x16-2)コードだけなのですが、 アメリカの規定ですから、数字や英文字といくつかの記号が規定できれば十分だったわけです。
因みに数字を表す場合は、最上位の1ビット目を符号として使用します。
1ビット目が1ならばマイナスの数字とみなすのです。例えば、
+1 は 0000 0001 (0x00)、-1 は 1111 1111 (0xFF)
+60 は 0011 1100 (0x3C)、-60 は 1100 0100 (0xC4)
2進数のプラス、マイナスを加算すると、桁上がりしてすべてゼロになります。
1バイトは8ビットなので、まだ半分残っています。そこに各メーカーは独自の文字をあてはめました。下記は JIS8 と富士通の EBCDIC(カナ)のコード表です。
JIS(ジス)とは Japanese Industrial Standards の略で、IBM社が開発したコード表ですが、文字通りこれが日本の規格になりました。
EBCDIC(エビシデック)とは Extended Binary Coded Decimal Interchange Code の略ですが、掲載したのは富士通オフコンのコード表(カナ)です。
ASCII(7ビットの表)は、JIS規格ではJIS7になりますが、その場合は、
0x5C “\”(BackSlash) は “\”(円マーク)
0x7C “¦”(縦破線)は ”|”(縦線)
0xEF の”~”(チルダ)は” ̄”(オーバーライン)に置き換わります。
(すべて半角と見てください)
JIS7/8を合わせてJISコードです。
3.漢字コード
漢字は2バイト(1ワード)を使用し、区点で表現する場合と16進数で表現する場合があります。
区点コードは10進数の2桁の区と、10進数の2桁の点の4桁の数字からなり、16進コードの上位バイトの1行が1区に該当し、1区の中に下位バイトの1行分が入ります。
文字コードでは両端の 0x20 と 0x7F を省きますので、区も点も 0x21(10進33)~0x7E(10進126)までで、94x94=8836 のマスに漢字を当てはめたコードをいいます。
区点コードでは、0101~9494、16進コードでは、0x2121~0x7E7Eです。
ところで、JIS漢字コードをみると、1バイト目を見ただけでは 半角の文字コードなのか漢字の1バイト目なのか判断がつきません。例えば、第一水準の最初の文字‘亜’は、JISコードでは '0x3021’です。 これを半角文字で表記すると、‘0 !’になります。
印字できるコードを使用したための当然の結果なのですが、 何らかの方法で、漢字コードであることを示す必要がありました。 そこで、漢字コードの前後を特別なコードで挟むことにしたのです。
それが制御コードの
0x0E (Shift-Out):ASCIIから離れ(漢字コードの開始)
0x0F(Shift-In):ASCIIに戻る(漢字コードの終了)
です。
しかし、このような制御コードを使用するのはメモリーの無駄使いになりますし、何よりも邪魔です。そこで、JIS8のコード表の、8列、9列、E列、F列には半角の文字が割り振られていないことを利用して、1バイト目が8列、9列、E列、F列であれば漢字コードだとみなすようにしたのが、Shift-JIS(シフトジス)です。(Shift-JIS は SJISとも表記します)
上位バイトは、0x81~0x9F、0xE0~0xFC、下位バイトは、0x40~0x7E、0x80~0xFC、つまり、
0x8140~0x817E、0xE080~0xFCFC の領域に、そっくりシフトされたのです。
登録可能数は、
上位バイトは0x81~0x9F(15+16=31)、0xE0~0xFC(16+13=29)の合計60通り、
下位バイトは0x40~0x7E(3x16+15=63)、0x80~0xFC(7x16+13=125)の合計188通りで
60X188=11280文字です。
JISからSJISへは基本的に変換が可能ですが、SJISには IBMやNECの拡張文字も登録されており、SJISからJISへは1部の文字が変換されません。
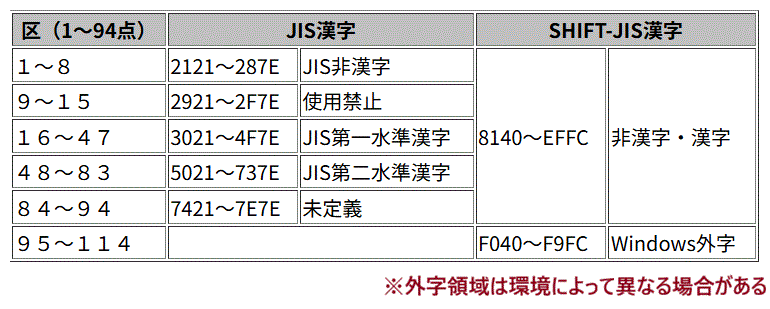
第一水準には、制定当時に比較的使用頻度が高いと思われた文字が、原則として音読みの50音順に、 第二水準には第一水準でもれた文字が部首・画数順に収録されています。
JIS規格は度々改定され、収録されている文字も増えていき、現在は第三水準、第四水準まであります。コードも区点番号の上位に面番号が追加され、面区点の3次元に拡張されました。
面番号は1と2までですが、JISx0208の漢字はすべて第一面にあります。そして、第一面の空き領域に第三水準の文字、 第二面には第四水準の文字が収録されるようになりました。
4.JEFコード
下記の表は富士通の マニュアルを参考にまとめた表です。
ホストは富士通オフコン、パソコンはWindowsです。
JEF基本非漢字と第1・2水準の漢字は、漢字JISコードと1対1の関係にあり、
JISコード + 0x8080 = JEFコードです。
16進でのコードは異なりますが、句点コードは同じです。
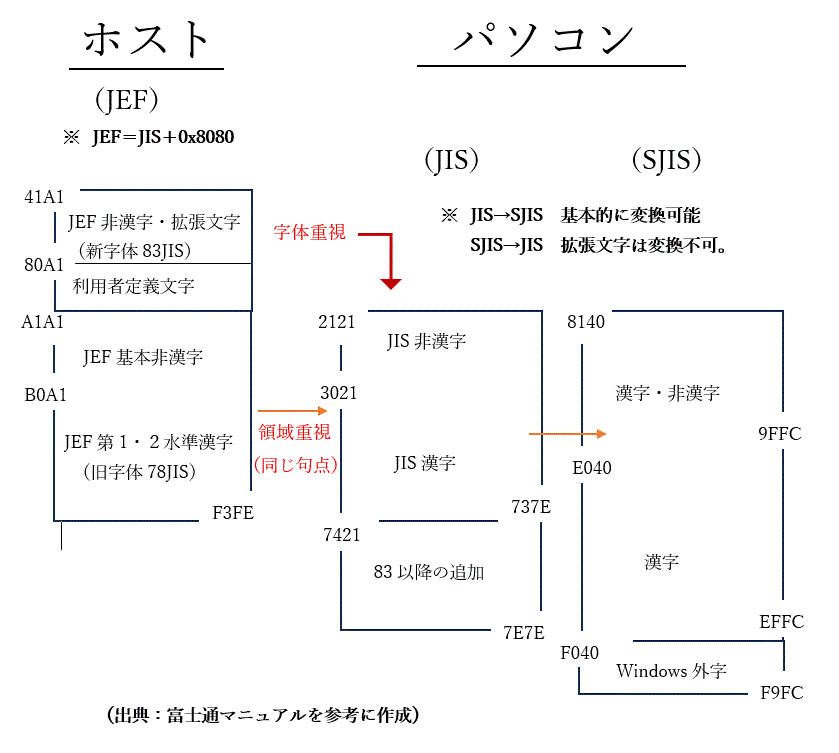
JEFからJISへの変換コマンドは、領域重視と字体重視の2通りが用意されているのですが、実際に実行してみると、どちらの方式でも一部の文字が変換されない現象が起きます。
原因は、JIS83の改訂版は、それ以前のJIS78とでは字形が異なることになったからです。
JIS78を旧字体、JIS83を新字体(統合文字または縮退文字)と呼ぶこともありますが、
JIS83では多くの文字が略字体風に改正されたからです。
Windowsなどの一般的なPC環境では、JIS83からの規格を引き継いでいますが、JEFコードはJIS78を基礎としており、改訂に伴うJEF側の対応は「旧字体はそのまま残して、新字体は拡張漢字域に収録する」でした。つまり、拡張域の漢字がJISと対応することになったのです。
その結果、JIS78(元々の領域重視)を基調とすると、 拡張漢字域に収録されている文字が変換されませんし、JIS83(字形を重視)からだと旧字体が変換されないことになりました。
一旦、JISの新字体に変換した後でJEFに変換しても旧字体には戻りません。
勿論、拡張漢字域の文字は JISコード + 0x8080 = JEFコード ではありません。
以上のことから、e-Taxへの当時の対応は、領域重視(JIS78)を採用せざるを得ず、未対応の文字についてはPGで置き換えました。
「個人の名前や企業名を縮退文字にしていいのか」とは思いますが、マイナンバーや法人番号も記載しますので、読めれば十分だということでしょう。
JEFコードには多くの漢字が収録されたおり、画面や帳票は多少なりとも見栄えよく設計することができ有難かったです。外字を作成することもほとんどありませんでした。
しかし、もはやJEFコードはCOBOLと同様に淘汰されていくのでしょうか? 残念です。
(掲載した資料と実行結果に関する記述は、2022年当時のものです)
